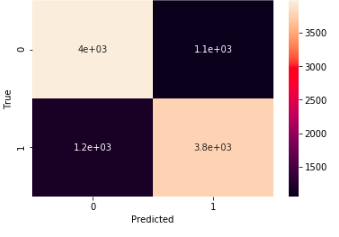
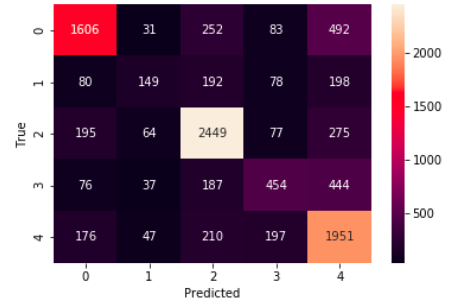
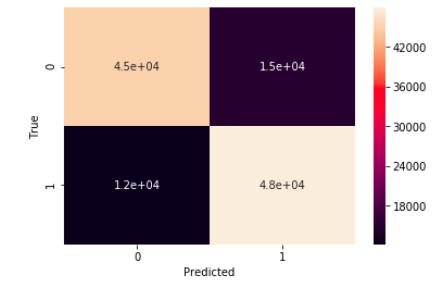
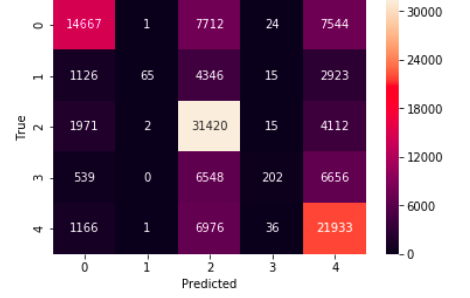
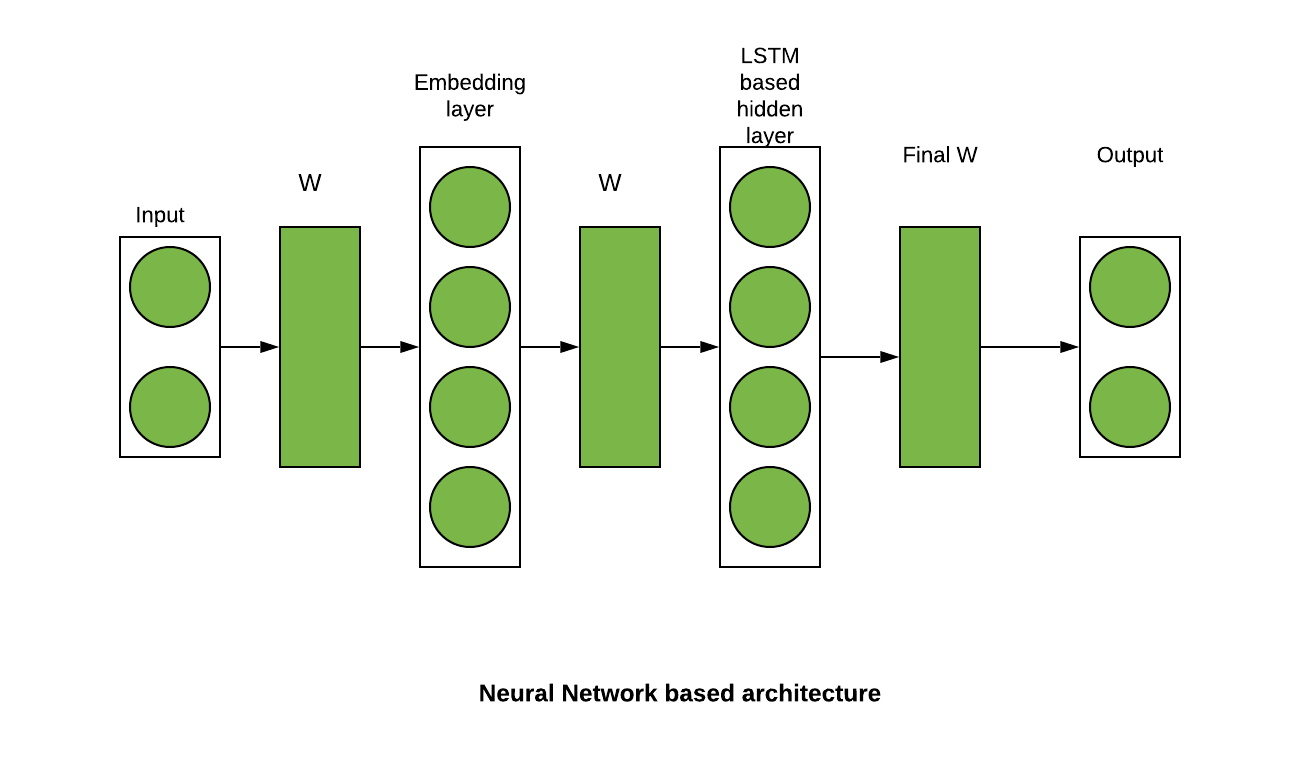
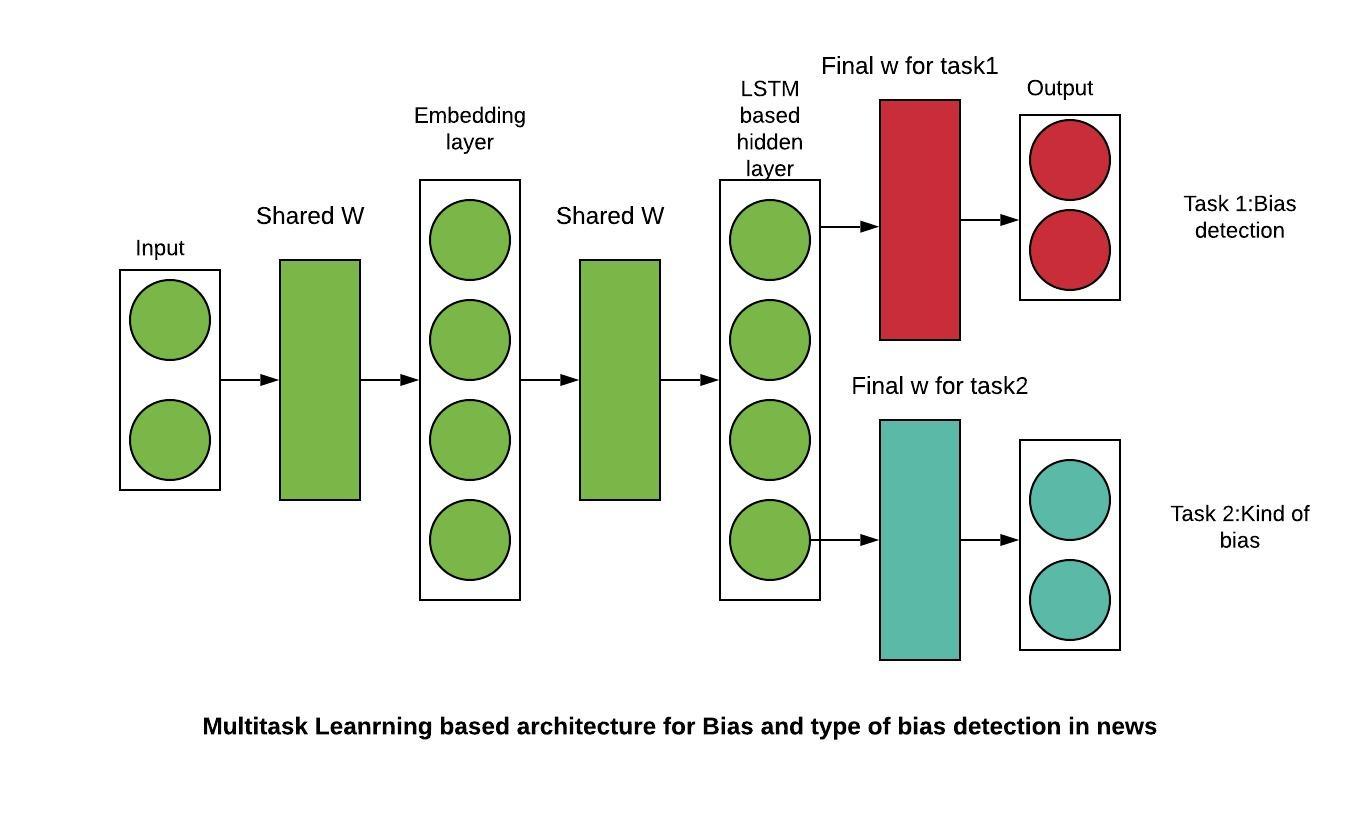
Hyperpartisan news is news that takes an extreme left-wing or right-wing standpoint. If one is able to reliably compute this meta information, news articles may be automatically tagged, this way encouraging or discouraging readers to consume the text. It is an important use case as most news and tweets these days are biased.

Problem Statement - Given the text and markup of an online news article, decide whether the article is hyperpartisan or not. The challenge of this task is to unveil the mimicking and to detect the hyperpartisan language, which may be distinguishable from regular news at the levels of style, syntax, semantics, and pragmatics. If an article is biased we also try to predict the type of bias in the article. The types of bias we are considering are- Right, Right-Center, Least, Left-Center, Left